





Introducing Llama 2: A ‘helpful’ text-generating model by Meta

In the ever-evolving landscape of artificial intelligence and natural language processing, Meta, a prominent technology company, has made a significant stride by releasing Llama 2—a more ‘helpful’ set of text-generating models. This cutting-edge development marks a new era in AI-generated content, promising greater accuracy, context awareness, and versatility for many applications.
Meta, formerly known as Facebook, has been at the forefront of AI research and innovation. Leveraging their extensive experience and expertise, they have unveiled Llama 2 as an advanced iteration of their previous text-generating models. With the rapid advancements in AI technology, creating more effective and human-like AI-generated text has been a paramount goal for companies like Meta.
The primary aim is to produce text that is not only coherent and linguistically accurate but also genuinely helpful and contextually relevant. Previous iterations of AI text generators faced challenges in maintaining relevance and coherence, often resulting in nonsensical or irrelevant output. However, Llama 2 addresses these limitations through its state-of-the-art architecture, leveraging the power of deep learning and natural language understanding.
Source: Meta
Advancements and Accessibility in AI Text Generation
Meta’s highly anticipated release of Llama 2 marks a significant evolution from its predecessor. While initially restricted and only available through requests to avoid potential misuse, Llama 2 takes a different approach, embracing wider accessibility. The model will be accessible for research and commercial use, and available for fine-tuning on prominent platforms such as AWS, Azure, and Hugging Face’s AI model hosting service.
In contrast to its cautious rollout of Llama, Meta has partnered with Microsoft to optimize Llama 2 for Windows, extending its reach to more users. Additionally, a collaboration with Qualcomm will bring Llama 2 to Snapdragon-powered devices, enabling users to harness its capabilities on smartphones and PCs in 2024.
So, what sets Llama 2 apart from its predecessor? Meta delves into the details in a comprehensive whitepaper. The new model comes in two variants: Llama 2 and Llama 2-Chat. Llama 2-Chat, specifically fine-tuned for two-way conversations, opens up exciting possibilities for interactive interactions with the AI.
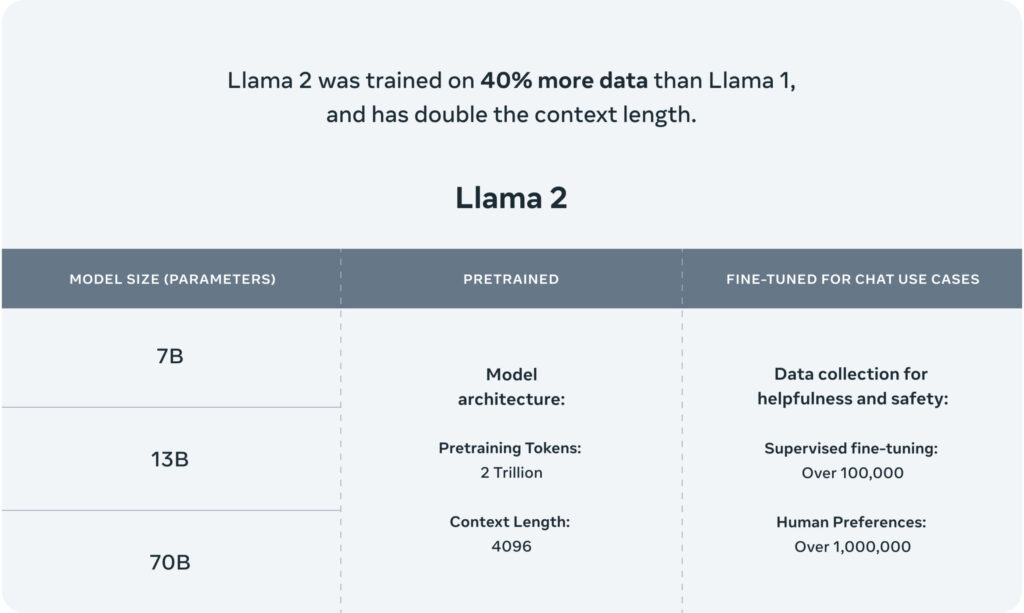
To cater to varying use cases and complexity levels, Llama 2 and Llama 2-Chat are further subdivided into different versions, based on their parameter count—7 billion, 13 billion, and an impressive 70 billion. In AI models, parameters are crucial components learned from training data, directly influencing the model’s performance in generating text.
Unveiling Imbalances and Training Data Challenges
Like most generative AI models, Meta admits Llama 2 contains biases along particular axes. Due to imbalances in the training data, it tends to generate “he” pronouns more than “she” pronouns. Additionally, toxic text in the training data prevents it from outperforming other models on toxicity benchmarks. Moreover, Llama 2 exhibits a Western skew, partly due to data imbalances featuring words like “Christian,” “Catholic,” and “Jewish.”
The Llama 2-Chat models fare better in Meta’s internal “helpfulness” and toxicity benchmarks. However, they tend to be overly cautious, declining some requests or including excessive safety details in their responses. Striking the right balance between safety and flexibility remains a challenge in fine-tuning AI models, and Meta acknowledges the need for ongoing improvement to address these limitations effectively.
A Powerful and Ethical AI Text Generation Model
Meta’s investment in training has been extensive, involving exposure to a massive two trillion tokens. Tokens represent units of raw text, such as individual words or subwords. This substantial training data surpasses Llama’s previous training set of 1.4 trillion tokens, significantly contributing to enhanced performance. In generative AI, the more tokens a model is trained on, the better its output will likely be.
While the whitepaper does not disclose the exact sources of the training data, it clarifies that the data is mainly derived from the web, predominantly in English, and focuses on “factual” content. Meta explicitly states that the data is not sourced from its products or services, underscoring the model’s impartiality.
With it’s expanded accessibility and advancements, the AI community eagerly anticipates its potential applications across various domains. As users and developers delve into the possibilities presented by this powerful text-generating model, responsible deployment remains paramount to ensure this cutting-edge technology’s ethical and constructive use.
We believe an open approach is the right one for the development of today's Al models.
Today, we’re releasing Llama 2, the next generation of Meta’s open source Large Language Model, available for free for research & commercial use.
Details ➡️ https://t.co/vz3yw6cujk pic.twitter.com/j2bDHqiuHL
— Meta AI (@MetaAI) July 18, 2023
“We believe that openly sharing today’s large language models will support the development of helpful and safer generative AI too,” Meta writes in a blog post. “We look forward to seeing what the world builds with Llama 2.”
In conclusion, Meta’s release represents a commendable step forward in text-generating models. With its enhanced contextual understanding, reduced bias, and commitment to ethical AI practices, it promises to be a valuable asset in the AI toolkit for various domains. As this technology becomes more accessible, it will be essential for users and developers to harness its potential responsibly and ensure a positive and constructive impact on society.
Source: Information @ Meta/ Technical Details









{kind=link}